目录
数据类型
数值
- rune是int32的别名(一般用来表示字符类型,其范围可以表示所有的Unicode编码,需要打印字符时要用%c作为占位符),byte是uint8的别名(存储的是字节值,可以用来存储和表示ASCII字符和处理二进制数据,如文件读写、网络通信等)。
- 当将一个整数转换为 byte 时,Go 会截取其低 8 位,并将其解释为无符号整数。(其它整数类型发生溢出时,行为也是相似的)
简便计算:byte类型的值,前面加负号,如
var a byte = 5,然后执行a = -a相当于a = byte(256 - int(a))的值,这样a的最终值为251。(底层原因是Go语言会将-5的补码 11111011 直接解释为无符号整数 251)
例如:
var b int8 = -128,然后执行fmt.Println(b==-b),结果为true,因为int8的范围是[-128,127],128会溢出。128 的二进制表示是 10000000 ,等于-128的补码,所以会被直接解释为-128。
-
有符号整数,其原码二进制最高位(最左边的位)通常用作符号位,0为正,1为负。
-
有符号整数,在现代计算机中通常用补码(最高位仍是符号位)表示(便于计算,可以直接通过加法实现减法运算,不存在双0问题),正整数的补码和原码一样,负整数的补码是其绝对值的原码各个位(包括符号位)取反后加1。
-
Go语言里面,八进制数以 0 开头,十六进制数以 0x 开头。
-
^在Go语言里面表示异或运算(相同为0,不同为1)
切片
切片的底层引用了数组,当切片截取了某个数组(也包括[0:0]),底层就会指向这个数组,除非append操作之后,超出原数组的容量范围,才会分配一个新的数组给切片作为底层。
数组和切片截取a[3:4:4],第一个为起始位置,第二个是截取结束位置,第三个是容量位置。
截取开始和截取结束位置可以大于长度位置,但必须小于等于容量位置。
容量位置必须大于或等于截取结束位置。如果省略第二个参数,则默认第二个参数为len(a),如果省略第三个参数,则默认第三个参数为cap(a)。
如果仅仅是通过下标取值,而不是截取,注意下标位置必须小于切片长度
计算切片长度,可以直接用第二个位置的值,减去第一个位置的值;计算切片容量,可以直接用第三个位置的值,减去第一个位置的值。
切片只能和nil进行比较(即使是未赋值的空接口也不能比较)。
所有不可比较类型都是只能和nil比较
对于切片(包括空切片和nil切片),可以在其容量范围内进行截取,其中没有元素的地方会用零值填充。省略截取结束位置参数时,默认为切片长度值。
nil切片截取之后仍是nil
s=[]int{}与s=make([]int,0)得到是空切片,var s []int得到的是一个nil切片。空切片底层指向同一个全局的空数组,nil切片底层是一个空指针。
数组和切片中可以指定下标[]int{5:1, 2, 3, 1:9, 10},未指定下标的,下标为前一个指定下标的位置加一,即为[]int{5:1, 6:2, 7:3, 1:9, 2:10},剩余的位置补0
当切片作为函数形参的时候,传递参数的时候,是引用传递,实际上传递的是一个包含底层数组指针、切片长度、切片容量的结构体。这个结构体本身是按照值传递的。所以函数内部接收的是一个副本,只不过这个副本指向通用的底层数组,长度和容量字段都是副本自己的。所以当函数内部执行append函数时,实际是改变了函数内部副本变量的长度和容量。
切片为nil时,也可以进行截取操作,如[:],截取后也等于nil,也可以进行len()、cap()操作
不允许对切片指针进行索引,但是数组指针可以
copy(dst,src)函数会复制切片内容,但是不会改变切片地址和大小,返回值是len(dst)、len(src)中的最小值。
直接使用fmt.Printf("%p",s),打印的是切片s的地址,获取底层数组地址需要通过
&s[0]获取,如果切片指向一个空数组,则无法获取数组的地址。
数组
数组各元素未赋值时,各元素默认为元素类型的零值。
数组指针为nil时,不能用来进行任何截取操作,但可以进行len()、cap()操作
特别注意
数组指针,即使为nil,也可以使用for range只迭代索引,使用len()、cap()仍然可以获取到数组的长度和容量,但这不是数组指针所指向的内容的长度,这是因为数组的长度是数组类型的一部分,而不是它值的一部分。对于固定大小的数组,其长度和容量在编译时就已经确定了。
如fmt.Println((*[3]int)(nil))打印出的值为nil,但是len((*[3]int)(nil))得到的长度为3。当使用for range (*[3]int)(nil)或者for k,_:=range (*[3]int)(nil)或for _,_=range (*[3]int)(nil)会循环三次,因为如果只迭代索引,Go的range机制不会解引用指针,而是直接计算长度(从类型信息获取),然后生成索引。但是不能使用for k,v:=range (*[3]int)(nil),也不能使用for _,v:=range (*[3]int)(nil),因为数组指针是nil,访问其所指向的数据会导致解引用空指针,所以在把数组元素赋值给v的时候,运行时会报空指针错误。
interface
interface包含了动态类型和动态值,判断是否等于另外一个interface,需要比较动态类型和动态值,先比较动态类型,如果动态类型不同,则直接返回结果。如果同态类型相同,则继续比较动态值。
如果动态类型相同,但却是不可比较类型,比如都是[]string这种类型,会发生panic(因为动态类型相同后,会比较动态值,但是动态值是不可比较类型的值)。
判断interface是否等于另外一个可比较类型(如Int、String)值,先比较interface的动态类型和后者类型,如果类型相同,然后再比较interface和后者的值
判断是否为nil时,需要动态类型和动态值都为nil,才相等。空interface与其他类型比较的时候(包括非interface类型),也是判断动态类型和动态值。
一个有方法的interface{},只能和 至少包含有这个接口的所有方法的interface{},空interface,nil 这三种比较。否则会编译不通过。
比如接口A只有方法hello()、Hi(),接口B也含有方法hello()、Hi(),另外B可能还含有其他方法,那么这两个接口是可以比较的
不可比较类型有map、slice、function、包含不可比较类型的结构体。
任何interface都可以类型断言为空interface,即x.(interface{})(如果x的动态类型实现了空interface{}类型对应的方法集合,就会成功,因为空interface{}本身已经是所有类型的实现了,所以除了动态类型为nil,必然成功),当动态类型为nil时,会断言失败(这么做一般没啥意义,实际开发中都是断言它的动态类型)。
结构体
结构体嵌套:某属性包含另一个结构体
结构体继承:直接包含另一个结构体,自动创建一个默认的同名字段,并且会继承父结构体的方法,子结构体可以直接调用父结构体的方法,子结构体也可以通过定义一个同样的方法来重写继承而来的方法(遵循就近原则)。
不同的结构体之间不可直接比较,即使字段相同,顺序相同,也不能直接比较。(直接比较会编译不通过)
结构体方法,可以通过结构体实例、结构体指针来调用(编译器会自动解引用,需注意空指针问题)
结构体指针方法,也可以通过结构体指针、结构体实例来调用(编译器会自动取地址,需注意是否可取地址)
结构体和结构体指针可以互相调用彼此的方法,这种灵活性是 Go 语言的设计特性,编译器会自动处理解引用和取地址。但是需要自己注意空指针问题、是否可取地址等。
多级指针不会进行自动解引用(如不支持**T自动解引用到*T),仅支持单级指针(*T)自动解引用到结构体。同样也不支持对结构体多层自动取地址(如不支持T自动取地址到&&T),仅支持对结构体单层取地址。(为了保持代码的清晰和安全性)
在接口赋值时,如果只有结构体方法实现了接口所有方法,结构体实例和结构体指针都可以赋值给接口(编译器会自动对结构体指针进行解引用)。但是如果只有结构体指针方法实现了接口所有方法,则只有结构体指针可以赋值给接口(编译器不会自动取地址)。
不允许在同一个类型上同时定义值接收者和指针接收者的同名方法(无论方法参数是否相同),否则编译不通过,这是GO的语言规范明确禁止。
如果值方法和指针方法加起来才满足实现接口,则可以把指针赋值给这个接口,而不可把值赋值给这个接口。
不能对不可寻址的结构体直接修改其属性,如Student{}.age=18无法通过编译。但是可以显式地创建一个指向结构体值的指针,如(&Student{}).age=18可以正常编译。(本质就是,结构体属性赋值,必须要能取地址,然后通过地址找到其属性的存储位置,然后赋值)
特别注意
在匿名值或字面量上调用指针接收者方法或者给结构体属性赋值时,编译器不会进行自动取址,因为会造成语义不明确或其他错误。比如结构体字面量,又比如函数返回值。
如Student{}.setAge()和getStudent().setAge(),会因为Student{}字面量和getStudent()返回的结构体无法自动取地址,而都不能直接调用指针方法setAge()。
可以创建一个变量接收值,然后用这个变量去调用方法。或者显式地创建一个指向结构体值的指针去调用方法(&Student{}).setAge()
iota
iota是常量计数器,只能在常量表达式中使用
iota在const关键字出现时,将重置为0,const中每新增一行常量声明将使iota计数一次。
如果在同一个const里面遇到新的iota,则恢复为常量计数器。不复制上一个值,也不是在上一个值的基础上加。
字符串
Go里面的字符串,是只读的,本质是一个只读的字节切片(由指针和长度组成),指向一段不可变的内存区域。有len()方法,可以进行s[0:3]截取,但是没有cap()方法,截取时也不能指定容量位置。
定义了一个字符串,不能直接通过下标去修改,否则会编译不通过。
任何修改操作(如拼接、替换)都会创建新的字符串,而非修改原字符串。
多个字符串可共享同一段底层数据(如子串操作 s[:3]不复制数据)
若需要修改字符串内容,可以转换为[]byte或 []rune后进行修改(每次转换都触发内存分配)
strings.Trim、strings.TrimLeft、strings.TrimRight都是从字符串,连续删除第二个参数中含有的任意字符。
相关信息
如strings.TrimRight(str, cutset) 是从字符串str的右边(也就是结尾处)开始,连续删除cutset中含有的任意字符(注意是字符,而不是字符串),直到遇不到cutset中的字符为止。
strings.TrimRight("ABBA", "BA")结果为空字符串,需要注意和strings.TrimSuffix的区别,strings.TrimSuffix是删除完整后缀。
拼接大量字符串可以使用strings.Builder或bytes.Buffer预分配缓冲区,避免多次内存分配。
bytes.Buffer还可以支持拼接字符和字符串。
map
Go里面map的值是通过键来访问的,不可以直接获取map中单个元素的地址,因为map中的值是不可寻址的,也就是说它们不能直接被取地址(不能对map的属性进行取地址,map底层是一个哈希表,当map重新哈希时,元素的存储位置可能会发生变化)。
相关信息
与map不同,切片的元素是可以寻址的。因为切片的底层是一个数组,元素的位置比较固定,除非切片重新分配内存,比如切片发生扩容(Go会分配一个新的且更大的内存空间,不支持在原地址进行扩展)、直接修改切片的底层数组,会导致元素的地址发生变化。
可以直接对map取地址,但是不能直接用map的指针来操作其属性,也就是说不能直接对map指针进行索引。
如果需要通过地址来访问map中的值,可以考虑使用类似这种格式map[int]*int,在map的value中保存真实的值地址,来达到类似的效果。
map没有cap方法,cap函数适用于数组、数组指针、slice、channel。
使用make初始化时,最多可以指定两个参数,如果指定了第二个参数,也没有实际意义,make(map[int]int, 2)后面的参数2没有意义。
map为nil也可以进行len()操作,也可以进行取值操作,但是取出的该类型的零值
Go语言中的map在并发读写时是线程不安全的,但并发读是可以安全的,前提是没有写操作在进行。
如果map属性值为结构体
当使用 . 操作符来访问或修改结构体值的字段时,Go编译器会自动进行指针解引用。(编译期)
因此当map的属性值为结构体时,无法通过map[key].A的形式来修改,因为会解引用失败,编译会失败。
而当map的属性值为结构体的指针时,可以通过map[key].A的形式来修改,因为这个过程不会进行解引用,而是直接使用指针修改结构体的属性值。
但是可以通过map[key].A的形式来读取,因为Go程序运行时,会对不可寻址的结构体进行值拷贝,然后对拷贝的值进行指针解引用。
函数
函数只能与nil进行比较。函数、map、切片、channel都只能与nil比较
当函数使用命名返回值变量时,要注意不能在隐式return时(也就是return后面不接变量名)被同名的局部变量遮蔽,否则会编译失败。解决的方式是在同名局部变量的作用域之外进行return,或者在同名局部变量的作用域内进行显式的return(也就是return后面接同名的变量名)
闭包:在定义一个函数时,函数捕获外层函数的局部变量,并且这些变量的生命周期被延长(从栈逃逸到堆,生命周期与闭包函数共存)
方法
值方法,可以通过指针来调用;指针方法,也可以通过值调用;这是因为编译器会自动进行转换
指针调用值方法时,自动解引用;值调用指针方法时,自动取地址。
空指针可以调用指针方法。
特别注意
空指针调用值方法,编译能通过,但运行的时候会因为解引用nil,从而导致panic。
使用字面量调用方法时,由于字面量不能进行取地址操作,所以编译器无法将值类型转换成指针类型。如A为自定义类型,PointMethod()为*A的方法,那么A(2).PointMethod(),将无法通过编译。
多级指针编译器不会自动转换。如A为自定义类型,ValueMethod()为A的方法,PointMethod()为*A的方法,那么**A类型无法直接调用ValueMethod(),并且也无法直接调用PointMethod()。
方法值
将方法赋值给一个变量时(或者作为函数参数传递时),实际上是将方法本身与它的接收者(值或指针)的副本绑定在一起,相当于拷贝了一份接收者的值,可以理解为快照,当方法被调用时,会使用这个副本值作为方法接收者,不会随原始变量改变。
如果方法的接收者需要解引用操作(比如使用指针调用值方法),那么在方法赋值给变量的时候,就会立即完成解引用。然后拷贝一份解引用后的值作为接收者值。
channel
不能关闭一个只能接受数据的单向channel,编译不通过。但是可以关闭一个只能发送数据的单向channel。(close()就是用来关闭发送的)
向一个nil的channel发生数据会导致goroutine阻塞,从一个nil的channel接收数据也会导致goroutine阻塞。
给一个已关闭的channel发送数据会导致panic,从一个已关闭的channel接收数据,会先收到缓冲区数据,然后收到零值。
双向通道可以转为单向通道,但是单向通道不能转为双向通道。比如a:=make(chan int),可以通过chan<- int(a)来转换。
<-符号前后可以留空格,也可以不留空格,都可以通过编译。
channel的底层实现
channel的底层是runtime包里面一个hchan结构体,这个结构体里面包含了互斥锁、缓存容量、当前元素数量、环形队列指针、环形队列的发送索引、环形队列的接收索引、待发送数据的goroutine队列、待接收数据的goroutine队列、是否已关闭等等。
golangtype hchan struct {
qcount uint // 当前队列中的元素数量(缓冲区已存在的数据量)
dataqsiz uint // 环形队列的大小(缓冲区大小)
buf unsafe.Pointer // 指向缓冲区的指针
elemsize uint16 // 单个元素的大小
closed uint32 // channel 是否已经关闭
sendx uint // 环形队列中的发送索引(向channel发送数据时,元素存放的缓冲区位置索引)
recvx uint // 环形队列中的接收索引(从channel接收数据时,读取的缓冲区位置索引)
recvq waitq // 等待接收数据的goroutine队列
sendq waitq // 等待发生数据的goroutine队列
lock mutex // 保护channel数据结构的互斥锁
...
}
flowchart LR
id1["goroutine A"] --发送数据--> ide1
subgraph ide1 [channel内部]
direction TB
id(channel)-->加锁
加锁 --是否已关闭--> C{closed}
C--已关闭-->unlock["解锁"]-->panic(panic)
C--未关闭-->D{是否有待接收数据的goroutine队列}
D--有等待接收的goroutine-->将数据交给最早挂起的接收者-->解锁-->id2("唤醒该goroutine")
D--无等待接收的goroutine-->E{是否有可用的缓冲区}
E--有可用的缓冲区-->id3["将数据放入缓冲区sendx位置"]
id3-->id6(调整sendx和qcount的值)-->unlock2["解锁"]
E--无可用的缓冲区-->id5("发送者goroutine A加入待发送数据的goroutine队列")-->unlock3["解锁"]-->id4["发送者goroutine A被阻塞"]
end
语法
defer
defer执行时机,return第一阶段(赋值,把将要返回的值赋值给变量进行存储,这个变量可能是具名变量或匿名变量)、执行defer进行收尾、return第二阶段(携带最终值退出)
defer在注册的时候(也就是入栈的时候),就已经确定了传入的参数值,也确定了函数体。如果参数值是函数调用,则在注册的时候,就会从左到右,立即依次计算出真正的参数值。如果是链式调用,defer注册时,就会先计算前面所有的函数,并把结果作为方法参数,只有最后一个函数会延迟执行。(闭包除外,闭包会等defer真正执行时,才会确定变量的值)
当函数内部发生panic时,该函数中所有的defer语句都仍然会被执行,当defer中发生panic时,会中止当前 defer 的执行,但会继续执行后续的 defer。
recover
recover的作用是捕获异常,recover()会使程序从panic中恢复,返回panic信息。
recover必须与defer一起使用,并且必须直接包含在defer注册函数的函数体中(在这个注册函数体中调用recover()时,可以defer cover()),可以是匿名函数中。不能进行多次封装或者嵌套。
注
recover()必须在panic的调用链上的某个defer函数中直接调用。也就是说recover()能捕获当前goroutine中所有尚未处理的panic,只要在同一个函数调用链,并且该panic发生在recover()所在的defer函数执行之前。
for range
- for range 在循环之前,就已经确定了循环的次数。
- for range 前面的临时变量,只会创建一次,然后每次重新赋值,即始终为同一个变量。
- 仅仅遍历切片,忽略具体业务时,普通的for语句的性能稍微更好一点,但是可以忽略,相差很小。主要是for range需要同时管理索引和值的获取。
- for range开始迭代时就浅拷贝了一个副本,对数组来说,相当于拷贝了一个新的数组进行迭代,修改原数组不会影响被迭代数组。而对于切片来说,range拷贝出来的切片与原切片底层是同一个数组,因此对原切片的修改也会影响到被迭代切片。
- for range 遍历的切片、map为nil,或者遍历的数组指针为nil时,不会报错。
- for range 前面可以不写变量,如
for range []int{1,2}也可以,只是无法获取元素值。 - for range 与 for k,v:=range 与 for k,_:=range 在内部实现上是由差异的。具体例子可以查看数组小节的特别注意
特别注意
如果在迭代切片循环的过程中,改变了原切片地址,则对原切片的修改不会影响被迭代切片。
比如在迭代的过程中,使用append给原切片追加元素导致扩容后,原切片的地址会发生改变,这时如果修改了原切片的元素,则不会影响到被迭代切片。
- for range也可以遍历一个数组指针,实际上是将数组的指针传递给被迭代的变量。这样,在被迭代的是数组引用的拷贝。另外即使被迭代的是数组指针,迭代出来的元素仍然是数组元素的副本,而不是指针(类似于切片引用传递)
for range 遍历数组指针比遍历数组更高效(避免整个数组拷贝,而是仅拷贝数组指针)
select case
对于case后面的表达式或语句,除了每个case的最后一步<-或->操作以外,其他操作的是根据case的顺序从上到下的执行,直到每个case都只剩下最后的<-或->操作。
注
例如下面会先执行A(),然后执行B(),等A()和B()都完成后,才会从case和deault中根据条件选一个执行里面的代码块。
select { case a<-A(): ... case b<-B(): ... default: ... }
对于包含通道通信操作的 select 语句,如果有多个 case 准备好的话(只剩下最后的<-或->操作,并且具备完成<-或->操作的条件),会进行随机选择。
所有的case都不满足时(都只剩下最后的<-或->操作,并且都不具备完成<-或->操作的条件),才会走default
for 与 select 的组合中,break只会跳出select块,然后从select块结束的地方继续执行,不会跳出for循环
for 与 select 的组合中,continue会从当前位置开始for的下一次循环,与直接在for循环中使用continue没有区别
switch case
switch后面没有条件时,默认为true。(如switch {等于switch true {)
switch后面的条件必须要和
{在同一行,否则由于golang会自动在switch行尾补充;进行断句。从而使是switch a()变为switch a();true {,switch条件由a()变为了true。
默认自带break,可以写fallthrough来贯穿case
所有的case都不满足时,才会走default
break label
单独的break表示退出当前循环
break label中label是放在循环之前的一个标识,可以明确的指出要退出哪个循环
init
同一个go文件里面,init执行顺序是从上到下。同一个package里面不同的go文件里的init执行是按照编译时读取文件的顺序。不同的package里面的init执行,是根据包名的英文字母排序执行(import后面的所有字母以/分隔对比每一项),如果有嵌套的,需要等到嵌套的init先执行,嵌套里的init也要根据字母顺序排队。golang中包的初始化,是串行执行的。如果有嵌套则按照如下图的顺序执行。
init函数不能被其他函数调用,包括main函数。
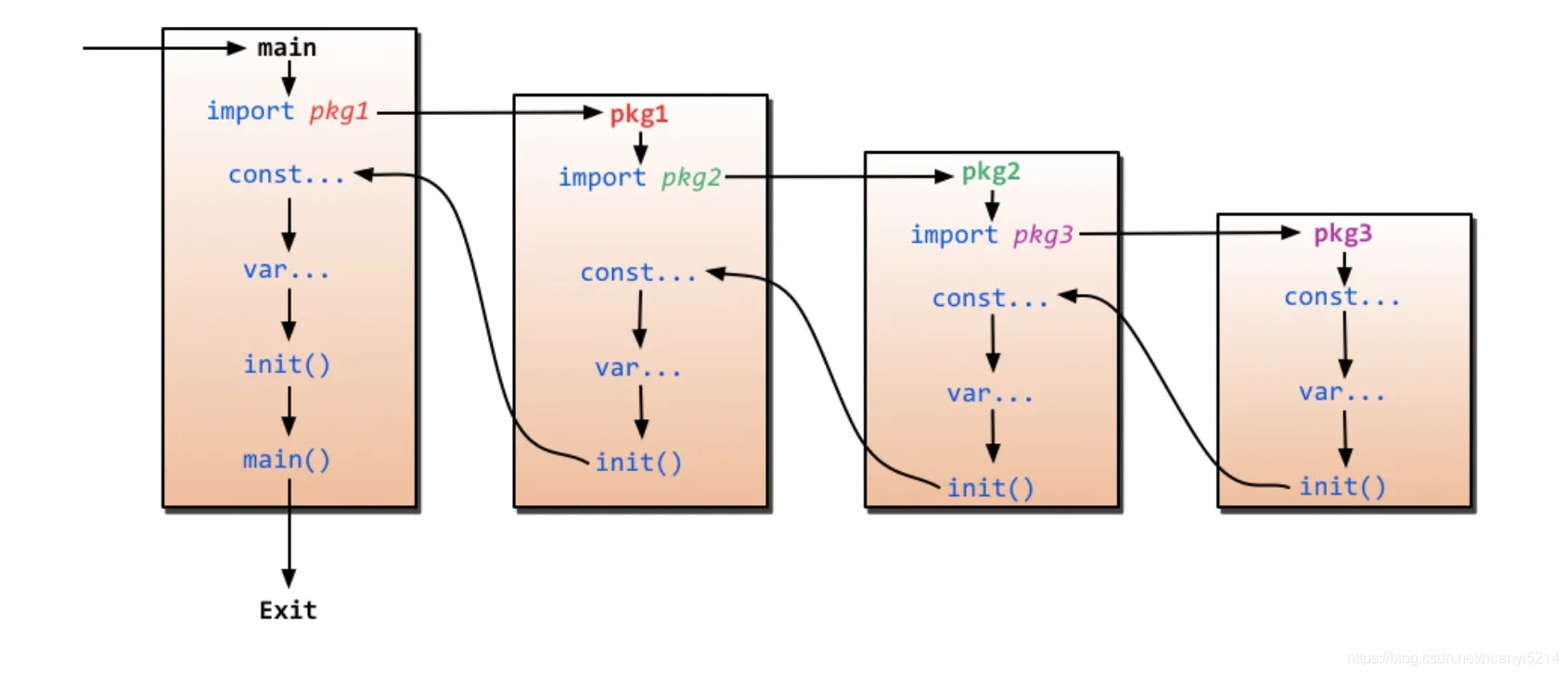
goto
goto跳转的目标标签,需要跟goto在同一级别或者更外层代码块。也就是说只能直接跳入同级和或者更外层代码块,不能跳入内层的代码块,也不能跳转到其他函数。
操作符
操作符优先级
.(成员访问操作符) 大于 [](索引操作符) 大于 *(解引用操作符) 等于 &(取地址操作符) 大于 ++或--(自增或自减操作符)
如对结构体
t的某个属性取地址可以直接&t.n,等价于&(t.n)
&和*都是右结合的,比如**p会先计算右边的*p,相当于*(*p)。
运算符优先级:一元运算符在一般的运算符中有最高的优先级。一元运算符包含"+"、"-"、"!"、"^"、"*"、"&"、"<-"。比如:5/+-*v 相当于5/(0+(0-(*v)))
注
左结合与右结合的区别:
- 左结合,从左开始计算,大多数算数运算符是左结合
- 右结合,从右开始计算,赋值运算符(=)、一元运算符等等
运算符^有两种用途:
- 二元运算符,按位异或,对应二进制位不同则为1,相同则为0
- 一元运算符,按位取反,0变1,1变0
赋值
不能使用短变量声明:=来设置字段值,无论是结构体、数组、切片、map等,如user.Age := 12会编译失败。
对于使用:=定义的变量,如果新变量与同名,已定义的变量不在同一个作用域中,那么 Go 会新定义这个变量
对于多值赋值语句,类似于a,b=1,2+a或者a,b:=1,2+a,执行顺序是从左到右,但是左边的运算结果不会影响右边的运算结果,他们都是独立的操作,表达式里面引用的都是这条语句之前的变量值。如果等号前面的不是变量,而是索引表达式(如s[i]),也同样是引用的是这条语句之前的s(包括所有属性,如len、cap等)
i++ 和 i–- 在 Go 语⾔中是语句,不是表达式,只能做为独立语句,不能赋值给另外的变量,这点与其他语言不一样。
常量与变量
变量
函数中声明的变量必须要使用,但是可以有未使用的全局变量。函数参数未使用也是可以的。
小妙招
如果有暂时没有使用的变量可以这样 _ = a或者b = b,也是可以的
不使用显式类型,无法用nil来初始化变量,如a:=nil会编译失败,因为编译器无法确定类型
使用字面量定义数组、切片、结构体、map等多元素类型时,如果最后一个元素跟}不在同一行,结尾也需要加逗号。
匿名变量
匿名变量是指在程序运行过程中产生的、没有显示绑定到变量名的中间值(临时值),如函数返回值、表达式计算结果。
在Go中不能对匿名变量取地址,因为匿名变量通常是临时存储在栈上,生命周期很短,如果允许取地址,可能导致悬挂指针(即指针指向已被释放的内存),破坏Go的内存安全保证。
常量
- 在Go语言中,常量是一个简单的标识符,不会被修改,常量未使用时能编译通过。
- 在Go语言中,常量是在编译时期就固定的值,是硬编码在程序中的值,并没有内存地址,所以是不可寻址的,因此不能取其地址。如果你尝试取一个常量的地址,就会报错,编译不通过。
- 无类型常量可以根据需要自动适配到其他类型,字面量是也是无类型常量,如
const a=1就是无类型常量,可以根据需要自动适配int、uint、int64、int32等类型 - const关键字只能用于定义基本类型的常量(即常量只能是基本类型),包括
布尔值、数值(整数、浮点数和复数)、字符串,以及基础类型为这些类型的自定义类型,如type A int - 不赋值的常量会在编译时,被赋值为上一个常量的值或者占位符常量的值,如果前面没有常量或者没有类似
_ int = 123这样的占位符定义,会编译不通过。
字面量
直接写在代码中的固定值,既可以是基本类型(如int,string),也可以是复合类型(如slice,struct)
小字面量(如基本类型),若字面量未逃逸且无需地址化,可能直接被编译为指令数据。若绑定到局部变量且未逃逸,分配在栈上。若字面量的地址逃逸(如返回指针或被闭包捕获),分配到堆上。
大字面量(如大数组或结构体),即使未逃逸,也可能直接在堆上分配(因栈空间有限)。
引用类型字面量,引用类型的字面量(如 slice、map、chan 的复合字面量)底层数据必定在堆上
普通指针的字面量,逃逸则堆,未逃逸则栈。
字符串字面量(如 "hello"),通常是只读的全局数据,在编译期存入程序的静态区(非堆非栈)。
字符串字面量赋值给变量时(如s:="hello"),的string头部结构可能分配在栈或堆,但数据始终指向静态区。而动态生成的字符串(如拼接、转换)会按逃逸分析规则分配内存。
基础类型的字面量(如 42, 3.14, "hello")是不能直接取地址的,但对于复合字面量(结构体、数组、切片、map),Go允许直接取地址(如p := &[]int{1, 2, 3})。当对复合字面量取地址时,编译器会先在栈或堆上分配内存(由逃逸分析决定),然后返回该内存的地址。
要注意字面量和匿名变量的区别:不能对匿名变量取地址,无论什么类型。
类型别名与类型定义
类型别名带有本身类型的所有方法
但是类型定义不具有原类型的方法
值类型与引用类型
- 值类型内存通常直接在栈中分配,
- 引用类型内存通常在堆上分配,变量本身仍然是在栈上存储其指针或引用的
注
在 Go 语言中,每个变量的内存分配都由编译器完成。对于大部分的变量,特别是小的数值类型、bool 类型、指针和短小的结构体等,它们的值会被直接存储在栈上。当你通过变量名访问这些变量时,程序会直接从栈上读取对应的值。
在运行时,Go 编译器已经决定了每个变量的存储位置,包括栈上的位置。这样,当你通过变量名访问变量时,程序会根据编译时决定的存储位置,在栈上定位变量的值并进行读取操作。
需要注意的是,Go 语言的变量可能也会被编译器进行逃逸分析,部分变量可能会逃逸到堆上进行分配,这通常发生在变量的生命周期跨越了编译器能够确定的范围,例如返回指针、闭包等情况。在这种情况下,对于逃逸到堆上的变量,通过变量名找到值的过程也会不同,需要通过堆上的指针进行访问。
总的来说,对于大部分情况下的变量,通过变量名找到栈上存储的值,是一个简单而高效的过程,由编译器的指令来实现。而对于逃逸到堆上的变量,访问方式会有所不同,通常需要通过堆上的指针来间接访问。
在 Go 语言中,函数返回的指针所指向的值,以及闭包变量的值,可能会存储在堆空间或者栈空间,具体取决于编译器的逃逸分析和优化行为。
逃逸分析是编译器在编译期间的一项重要工作,用于决定变量的生命周期。对于那些在函数结束后不再被引用的变量,编译器可以优化地不分配栈空间,而是将其分配到堆上。这种情况下,函数返回的指针所指向的值以及闭包变量的值就会存储在堆空间中。
对于那些逃逸到堆空间的变量,它们的生命周期可能会比函数的生命周期更长,所以编译器会将它们分配到堆上,以便随时可以被访问。
需要注意的是,即使变量的值存储在堆上,变量本身的指针或引用可能仍然存储在栈上。这样的设计既充分利用了栈空间的高效性,又能够避免因为局部变量的生命周期而带来的额外开销。而对于较大的数据或者生命周期较长的变量,将其分配到堆上可以减少栈空间的使用,并优化内存的管理和利用。
因此,函数返回的指针所指向的值,以及闭包变量的值,可能存储在堆空间或栈空间,具体取决于编译器的逃逸分析决策。
关键字与预定义标识符
关键字
用于语法结构和流程控制,具有特点的语法功能和含义,不能用作变量名和函数名,Go语言中有25个关键字,如break、const、var、func、struct等等
预定义标识符
预先定义的标识符,包括基本类型、常量、nil、内建函数等,可以在代码中重新定义或作为变量名被赋值,Go语言中有37个预定义标识符,如int、string、bool、true、false、iota、nil、len、cap、append、make、new等等
同步
互斥锁
sync.Mutex是值类型。当互斥锁作为方法的接收者或者参数时,要注意避免值复制,否则会导致互斥锁不生效(因为是两个不同的锁)。Lock()与Unlock()方法的接收者为指针类型*sync.Mutex,所以当需要把sync.Mutex进行函数传参时,一般传入同一个sync.Mutex变量的指针,这样可以保证加锁和解锁作用于同一个sync.Mutex变量。
相关
不仅仅是sync.Mutex变量,sync.WaitGroup也不要进行值传递,因为它们会作用于不同的实例。
当 sync.Mutex 变量直接赋值给另一个变量时,它的当前状态(即 state 字段,类型为 int32,记录互斥锁的状态)也会被复制过去。而 sync.WaitGroup 由于是不可复制的类型,如果将一个 sync.WaitGroup 变量赋值给另一个变量,编译器会报错。
sync.WaitGroup在调用Wait()方法执行完成后,可再继续调用Add()方法和Wait(),但是不能在Wait()调用的同时,去调用Add(),否则会报运行时错误,这是为了防止数据竞争。
运行时
GC
垃圾回收器(GC)负责管理内存,它会识别和回收不再被引用的数据空间,无论它们是在堆上分配还是在栈上分配的。
调度
goroutine进入“就绪”状态后才会被放入调度队列,等待调度器为其分配CPU时间片后进行执行。
本文作者:枣子
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!